
From fit for purpose development to pie in the sky research, this is what AI looks like in 2020.
After releasing what may well have been the most comprehensive report on the State of AI in 2019, Air Street Capital and RAAIS founder Nathan Benaich and AI angel investor and UCL IIPP visiting professor Ian Hogarth are back for more.
In the State of AI Report 2020, Benaich and Hogarth outdid themselves. While the structure and themes of the report remain mostly intact, its size has grown by nearly 30%. This is a lot, especially considering their 2019 AI report was already a 136 slide long journey on all things AI.
The State of AI Report 2020 is 177 slides long, and it covers technology breakthroughs and their capabilities, supply, demand, and concentration of talent working in the field, large platforms, financing, and areas of application for AI-driven innovation today and tomorrow, special sections on the politics of AI, and predictions for AI.
ZDNet caught up with Benaich and Hogarth to discuss their findings.
AI democratization and industrialization: Open code and MLOps
We set out by discussing the rationale for such a substantial contribution, which Benaich and Hogarth admitted to having taken up an extensive amount of their time. They mentioned their feeling is that their combined industry, research, investment, and policy background and currently held positions give them a unique vantage point. Producing this report is their way of connecting the dots and giving something of value back to the AI ecosystem at large.
Coincidentally, Gartner’s 2020 Hype cycle for AI was also released a couple of days back. Gartner identifies what it calls 2 megatrends that dominate the AI landscape in 2020: Democratization and industrialization. Some of Benaich and Hogarth’s findings were about the massive cost of training AI models, and the limited availability of research. This seems to contradict Gartner’s position, or at least imply a different definition of democratization.
Benaich noted that there are different ways to look at democratization. One of them is the degree to which AI research is open and reproducible. As the duo’s findings show, it is not: only 15% of AI research papers publish their code, and that has not changed much since 2016.
Hogarth added that traditionally AI as an academic field has had an open ethos, but the ongoing industry adoption is changing that. Companies are recruiting more and more researchers (another theme the report covers), and there is a clash of cultures going on as companies want to retain their IP. Notable organizations criticized for not publishing code include OpenAI and DeepMind:
“There’s only so close you can get without a sort of major backlash. But at the same time, I think that data clearly indicates that they’re certainly finding ways to be close when it’s convenient,” said Hogarth.
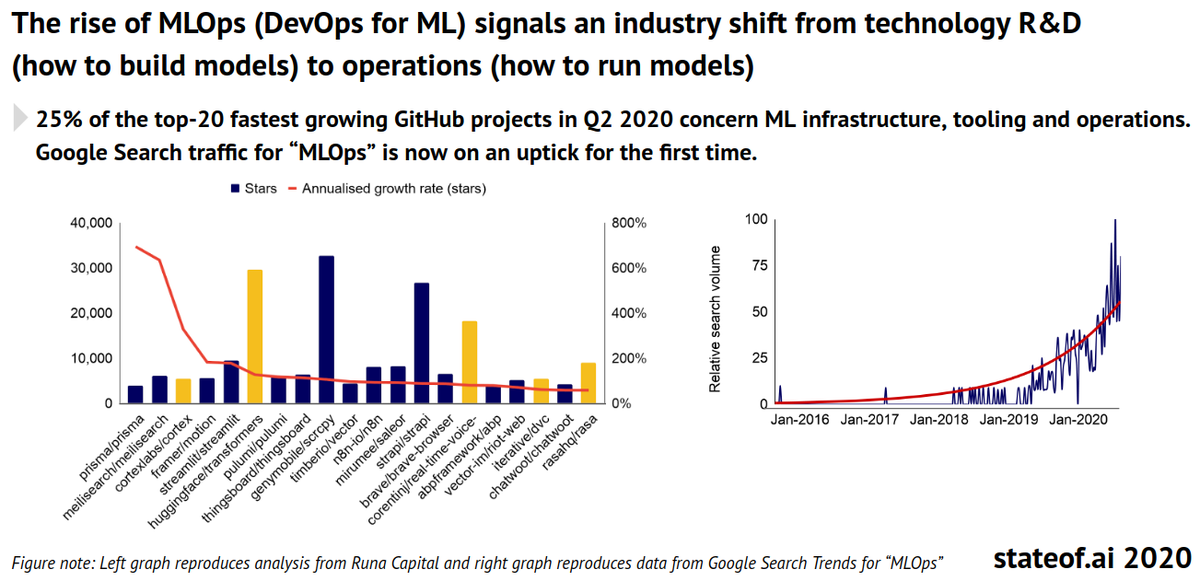
Industrialization of AI is under way, as open source MLOps tools help bring models to production
As far as industrialization goes, Benaich and Hogarth pointed towards their findings in terms of MLOps. MLOps, short for machine learning operations, is the equivalent of DevOps for ML models: Taking them from development to production, and managing their lifecycle in terms of improvements, fixes, redeployments, and so on.
Some of the more popular and fastest-growing Github projects in 2020 are related to MLOps, the duo pointed out. Hogarth also added that for startup founders, for example, it’s probably easier to get started with AI today than it was a few years ago, in terms of tool availability and infrastructure maturity. But there is a difference when it comes to training models like GPT3:
“If you wanted to start a sort of AGI research company today, the bar is probably higher in terms of the compute requirements. Particularly if you believe in the scale hypothesis, the idea of taking approaches like GPT3 and continuing to scale them up. That’s going to be more and more expensive and less and less accessible to new entrants without large amounts of capital.
The other thing that organizations with very large amounts of capital can do is run lots of experiments and iterates in large experiments without having to worry too much about the cost of training. So there’s a degree to which you can be more experimental with these large models if you have more capital.
Obviously, that slightly biases you towards these almost brute force approaches of just applying more scale, capital and data to the problem. But I think that if you buy the scaling hypothesis, then that’s a fertile area of progress that shouldn’t be dismissed just because it doesn’t have deep intellectual insights at the heart of it.”
How to compete in AI
This is another key finding of the report: huge models, large companies, and massive training costs dominate the hottest area of AI today: NLP (Natural Language Processing). Based on variables released by Google et. al., research has estimated the cost of training NLP models at about $1 per 1000 parameters.
That means that a model such as OpenAI’s GPT3, which has been hailed as the latest and greatest achievement in AI, could have cost tens of millions to train. Experts suggest the likely budget was $10 million. That clearly shows that not everyone can aspire to produce something like GPT3. The question is: Is there another way? Benaich and Hogarth think so and have an example to showcase.
PolyAI is a London-based company active in voice assistants. They produced and open-sourced a conversational AI model (technically, a pre-trained contextual re-ranker based on transformers) that outperforms Google’s BERT model in conversational applications. PolyAI’s model not only performs much better than Google’s, but it required a fraction of the parameters to train, meaning also a fraction of the cost.
PolyAI managed to produce a machine learning language models that performs better than Google in a specific domain, at a fraction of the complexity and cost.
The obvious question is: How did PolyAI do it? This could be an inspiration for others, too. Benaich noted that the task of detecting intent and understanding what somebody on the phone is trying to accomplish by calling is solved in a much better way by treating this problem as what is called a contextual re-ranking problem:
“That is, given a kind of menu of potential options that a caller is trying to possibly accomplish based on our understanding of that domain, we can design a more appropriate model that can better learn customer intent from data than just trying to take a general purpose model — in this case BERT.
BERT can do OK in various conversational applications, but just doesn’t have kind of engineering guardrails or engineering nuances that can make it robust in a real world domain. To get models to work in production, you actually have to do more engineering than you have to do research. And almost by definition, engineering is not interesting to the majority of researchers.”