
Data warehouses alone don’t cut it. Data lakes alone don’t cut it either. So whether you call it data lakehouse or by any other name, you need the best of two worlds, says Databricks. A new query engine and a visualization layer are the next pieces in Databricks’ puzzle.
Databricks announced today two significant additions to its Unified Data Analytics Platform: Delta Engine, a high-performance query engine on cloud data lakes, and Redash, an open-source dashboarding and visualization service for data scientists and analysts to do data exploration.
The announcements are important in their own right since they bring significant capabilities to Databricks’ platform, which is already seeing good traction. However, we feel it’s important to put them in the context in the greater scheme of things.
ZDNet connected with Databricks CEO and co-founder Ali Ghodsi to discuss the Data Lakehouse vision and reality, and where do Delta Engine and Redash fit in. To listen to the discussion, check the Orchestrate All the Things podcast.
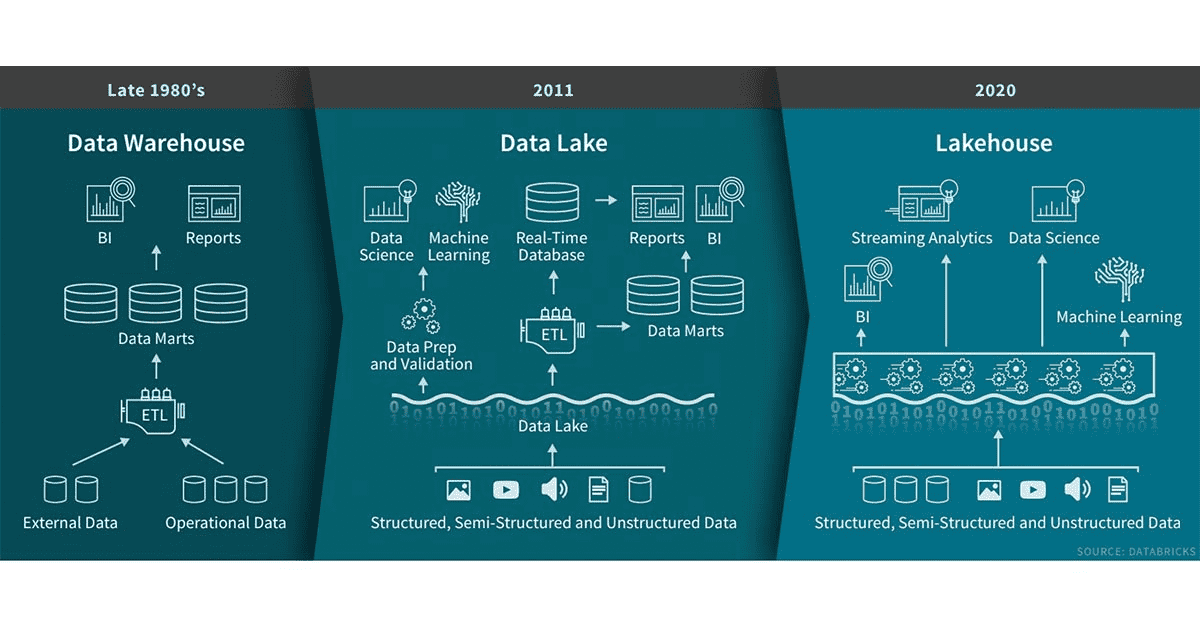
Data warehouses, data lakes, data lakehouses
Databricks was founded in 2013 by the original creators of Apache Spark to commercialize the project. Spark is one of the most important open-source frameworks for data science, analytics, and AI, and Databricks has grown in importance over the years as well.
Earlier this year, Databricks started floating the term Data Lakehouse, to describe the coalescing of two worlds, and words: Data warehouses and data lakes. Some people liked the term and the idea; others were more critical. No matter, argues Ghodsi, because this is happening anyway, with or without the term, with or without Databricks.
Databricks defines Data Lakehouses as having a number of properties that traditionally are associated with data warehouses, such as schema enforcement and governance and support for business intelligence, and others traditionally associated with data lakes, such as support for diverse data types and workloads.
The Databricks definition of a data lakehouse
Ghodsi cited two major trends as the driving force for the emergence of the Data Lakehouse: Data science and machine learning and multi-cloud. Neither of those existed at the time data warehouses were first implemented. Data lakes tried to address those, but they have not always succeeded.
As Ghodsi mentioned, data warehouses are not good at storing unstructured data such as multimedia, which is often what is needed for machine learning. Plus, he went on to add, data warehouses use proprietary formats — which means lock-in — and the cost of storing data rises steeply with the volume of data.
Data lakes, on the other hand, don’t have those issues — they have different ones. First, they often become “data swamps,” because they do not provide any structure, which makes it hard to find and use the data. Plus, their performance is not great, and they don’t support business intelligence workloads — at least not in their initial incarnation.
So, what is the Databricks’ answer on how to bring those two worlds together? What are the building blocks of the Data Lakehouse?
How much schema do you need and when?
The first part of the equation, Ghodsi said, is a common, non-proprietary storage format, plus transactional properties: Delta Lake, which has already been open-sourced by Databricks. The other part is a fast query engine, and this is where Delta Engine comes in. Still, we were not entirely convinced.
What we see as the major differentiation between data warehouses and data lakes is governance and schema. This is the dimension on which these approaches sit on opposite sides of the spectrum. So, the real question is: How does the Databricks vision of a Data Lakehouse deal with schema?
Data warehouses have schema on write, which means all data has to have a schema upfront, at the moment of ingestion. Data lakes have schema on read, which means data can be ingested faster and without making a priori decisions, but then deciding what schema applies to the data and even finding the data becomes a challenge.
The Databricks answer to that is called Schema Enforcement & Evolution. Ghodsi framed it as having a cake and eating it, too. The way it works is that it is possible to store data without enforcing a schema. But then if you want to format data into tables, there are different levels of schema enforcement that can apply. In addition to schema enforcement, schema evolution enables users to automatically add new columns of rich data:
Data lakes, data warehouses, and the data lakehouse. The term was coined in 2016 by Pedro Javier Gonzales Alonso.
“The raw tables, they might be in any particular format and they actually are. Essentially schema on read tables. And then after that, you move your data into a bronze table, then after that into a silver table, and after that into a gold table. At each of these levels, you’re refining your data and you’re putting more schema enforcement on it,” Ghodsi said.
That’s all fine and well, although how this approach compares to a more fully-fledged data catalog is another issue. We could not help but note, however, that this is essentially something Databricks’ Data Lakehouse enables users to do but does not necessarily support them in doing.
Ghodsi pointed out that there are certain training programs that Databricks users can attend, and its architects follow the approach and spread the word, too. In the end, however, just like data warehouses have a certain way of thinking people have to subscribe to, the same applies here.
If you want to get with the Data Lakehouse program, the technology alone won’t cut it. You have to adopt the methodology too, and this is something you should be aware of. And with that, we can move to Delta Engine and Redash and see where exactly they fit in the big picture.
Delta Engine and Redash: A fast query engine, and the missing piece in visualization
When we mentioned data lakes and how they don’t support business intelligence workloads previously, you may have noticed how we noted that’s not entirely true these days. By now, a number of SQL-on-Hadoop engines have enabled business intelligence tools to connect to data lakes.
Some of these engines, like Hive or Impala, have been around for a while. So, the question on Delta Engine is: How is it different? What it boils down to, Ghodsi said, is that it’s much faster. We’ll skip the deep dive, which ZDNet’s Andrew Brust will do tomorrow, but suffice it to say that Delta Engine is written in C++, and it uses vectorization.
That can make a difference in the engine’s performance, which in turn can make a difference in interactive query workloads. On hearing the analysis from Ghodsi, we ventured on a prediction: We figured Delta Engine may not follow the lead of its predecessors. Databricks’ policy has been to initially start projects for its own use, and then open-source them, which is what happened with Delta Lake.
But it sounded like Databricks invested a lot in Delta Engine, and it’s a differentiation point too. Though the answer is not clear, it’s safe to say if Delta Engine will be open-sourced. It won’t happen soon. Open source, however, is a key theme in the acquisition of Redash.
Redash visualizations will become part of Databricks’ stack, as it was “love at first sight”. Image: Databricks
Apache Spark, on which Databricks’ platform is based, excels at streaming and batch analytics, as well as machine learning and more code-oriented data engineering work. But neither open-source Spark nor the commercial Databricks platform are focused on visual data pipeline authoring or the full range of connectors necessary to move data from enterprise SaaS applications.
The above paragraph, identifying missing pieces in Databricks’ stack, was written by Brust recently. By acquiring Redash, the visualization missing piece is no longer missing. Databricks and Redash are similar and complementary: They are good at what they do — a back-end and front-end for data, respectively — and they capitalize on open source products, which they offer as managed solutions in the cloud.
Databricks did need a visualization solution for its stack — there’s no question about that. The real question is: Why acquire Redash? Databricks could have gotten the missing piece of the puzzle via a partnership. Or, if they wanted Redash’s technology, they could have just gotten it — it’s open source. To us, this looked like an acqui-hire.
Ghodsi more or less confirmed this. He said it was “love at first sight” with Redash; they liked the product, and they aligned with the team, so they decided to bring them onboard to fully integrate Redash in Databricks’ stack. The core Redash product will remain open source. Why not just get the technology?
“Oftentimes there is actually a factory behind these software artifacts, the factory that builds them. Exactly how that factory works… no one from the outside ever really knows how they actually build the software. And when you acquire the company, you get the whole factory. So you know that it’s going to work,” Ghodsi said.
Accelerating the future
Discussing how the Redash team will be integrated into Databricks brought us to the business recap part of the conversation. A few months back, Ghodsi had stated that Databricks is seeing remarkable growth. We wondered whether that momentum is holding up. We figured the last few months may actually have helped, given the nature of what Databricks does. Ghodsi concurred:
“The pandemic is accelerating the future. People are getting rid of cash. They’re doing more telemedicine, more video conferencing. AI and machine learning is part of that future. It is the future. So it’s getting accelerated, more and more CFOs are saying — let’s actually double down on more automation. Cloud is another thing that is inevitable. Eventually, everybody will be in the cloud. That’s also accelerated.
So those are positive trends. Plus, a lot of startups have been laying off people or hiring freezes. We’ve been fortunate that we’ve sort of planned for an economic downturn, so we were really set up for hitting the gas and accelerating when this happened. For instance, we started hiring and we see a significant boost in hiring. The other thing is that we’re well capitalized, because we’ve been sort of saving money for this.”
Well capitalized indeed — Databricks is fresh from raising a massive $400 million funding round. Of course, it’s every CEO’s job to tell the world that their company is doing great. In this case, however, it looks like Databricks is riding with the times indeed.
The new pieces of the puzzle, Delta Engine and Redash, seem to fit well into the big picture. What remains to be seen is, how well the Databricks recipe for data governance and schema management works in practice for those who adopt it.
Content retrieved from: https://www.zdnet.com/article/data-lakehouse-meet-fast-queries-and-visualization-databricks-unveils-delta-engine-acquires-redash/.