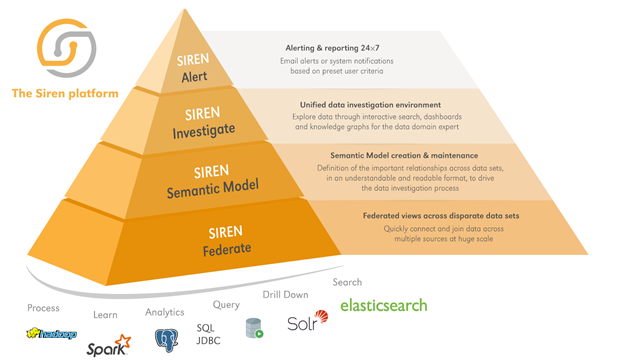
Siren promises the benefits of knowledge graphs, without the hassle of reinventing your existing data management and infrastructure Graph databases are amazing, but the knowledge graph is in your data already. That’s the key message Siren has been advocating,...
Neo4j just launched its cloud offering, which it says will make graph mainstream. We discuss the offering with CEO Emil Eifrem, and take a look at where the graph market is right now. Neo4j Aura, a fully managed native graph Database as a Service (DBaaS), has just...
Neo4j just launched its cloud offering, which it says will make graph mainstream. We discuss the offering with CEO Emil Eifrem, and take a look at where the graph market is right now. Neo4j Aura, a fully managed native graph Database as a Service (DBaaS), has just...
When driving a vehicle, milliseconds matter. Autonomous vehicles are no different, even though it may be your AI that drives them. AI = data + compute, and you want your compute to be as close to your data as possible. Enter edge computing. We all know and love the...
When driving a vehicle, milliseconds matter. Autonomous vehicles are no different, even though it may be your AI that drives them. AI = data + compute, and you want your compute to be as close to your data as possible. Enter edge computing. We all know and love the...